
پردازنده کوانتومی بهبود یافته گوگل به اندازه کافی برای تصحیح خطا خوب است.
خلاصه: با افزایش تعداد کیوبیتها در پردازندههای کوانتومی، میزان خطای موجود در مجموعه هم افزایش پیدا میکند. بهنحوی که امکان انجام محاسبات با آنها عملاً وجود ندارد. گوگل برای اولین بار توانسته است با استفاده از ایده کیوبیتهای منطقی، تصحیح خطا در پردازندههای کوانتومی را سادهتر کند.
گوگل اعلام کرده است امکان اجرای تصحیح خطای کوانتومی روی نسل بعدی پردازندههای کوانتومی این شرکت، Sycamore، وجود دارد. تغییراتی که برای بهبود عملکرد روی Sycamore انجام شده است زیاد نیست، یعنی تعداد کیوبیت تغییر نکرده است و تنها عملکرد آن بهتر شده است. انجام تصحیح خطای کوانتومی واقعاً یک خبر نیست – این گروه چند سال پیش موفق شده بودند این کار را انجام دهند. در نسلهای قبلی پردازندهها، کیوبیتها به اندازهای مستعد خطا بودند که افزودن تعداد بیشتری از آنها به یک طرحواره تصحیح خطا باعث ایجاد مشکلاتی میشد که از تصحیحی که انجام میشد، بزرگتر بود. در این ورژن جدید، افزودن کیوبیتهای بیشتر و کاهش نرخ خطا بهطور همزمان امکانپذیر شده است.
ما میتوانیم آن را درست کنیم
واحد عملیاتی یک پردازنده کوانتومی یک کیوبیت است، که میتواند یک اتم، یک الکترون، یا یک قطعه الکترونیک ابررسانا باشد – از این کیوبیت میتوان برای ذخیره و دستکاری یک حالت کوانتومی استفاده کرد. هر چه کیوبیتهای بیشتری داشته باشید، دستگاه توانایی بیشتری دارد. بهنحوی که تصور میشود زمانی که به چند صد کیوبیت دسترسی داشته باشید، میتوانید محاسباتی انجام دهید که انجام آنها با استفاده از کامپیوتر کلاسیکی کاری دشوار و حتی غیرممکن است.
این امر با فرض اینکه همه کیوبیتها درست رفتار کنند امکانپذیر است؛ که در واقعیت اینطور نیست. استفاده از کیوبیتهای بیشتر باعث میشود احتمال مواجهه با خطا بیشتر شود. در حال حاضر ما کامپیوترهای کوانتومی با بیش از 400 کیوبیت داریم، اما تلاش برای انجام هرگونه محاسبهای که به تمام 400 کیوبیت نیاز دارد، با شکست مواجه میشود.
راهحلی که برای این مشکل ارائه شده است این است که یک کیوبیت منطقی تصحیح خطا شده (به انگلیسی: error-corrected logical qubit ) تولید کنیم. برای این کار باید یک حالت کوانتومی را بین مجموعهای از کیوبیتهای متصل، توزیع کنیم. (از نظر منطق محاسباتی، همه این کیوبیتهای سختافزاری را میتوان به عنوان یک واحد درنظر گرفت، که به آن “کیوبیت منطقی” میگویند.) تصحیح خطا توسط کیوبیتهای اضافی که در نزدیکی هر کیوبیت منطقی قرار میگیرند، امکانپذیر میشود. برای پیدا کردن حالت هر کیوبیتی که بخشی از کیوبیت منطقی است، روی این کیوبیتهای اضافه اندازهگیری انجام میشود. اگر یکی از کیوبیتهای سختافزاری که بخشی از کیوبیت منطقی است، خطا داشته باشد، این واقعیت که فقط کسری از اطلاعات کیوبیت منطقی روی این کیوبیت سوار شده است، به این معنی است که حالت کوانتومی خراب نشده است. و اندازهگیری همسایههای آن خطا را آشکار می کند و امکان دستکاری کوانتومی برای رفع آن را فراهم میکند.
هر چه کیوبیتهای سختافزاری بیشتری را به یک کیوبیت منطقی اختصاص دهید، کیوبیت منطقی مقاومتر خواهد بود. در حال حاضر فقط دو مشکل وجود دارد. یکی این است که ما تعداد کافی کیوبیتهای سختافزاری نداریم. در حال حاضر، اجرای یک طرح تصحیح خطای مقاوم روی پردازندههایی با بیشترین تعداد کیوبیت ممکن، باعث میشود ما کمتر از 10 کیوبیت برای محاسبه داشته باشیم. مسئله دوم این است که نرخ خطای کیوبیتهای سختافزاری برای چنین کارکردی بیش از اندازه بالاست. افزودن کیوبیتهای موجود به یک کیوبیت منطقی آن را مقاومتر نمیکند. بلکه باعث می شود که احتمال وجود خطاهای زیادی در یک زمان وجود داشته باشد که نتوان آنها را اصلاح کرد.
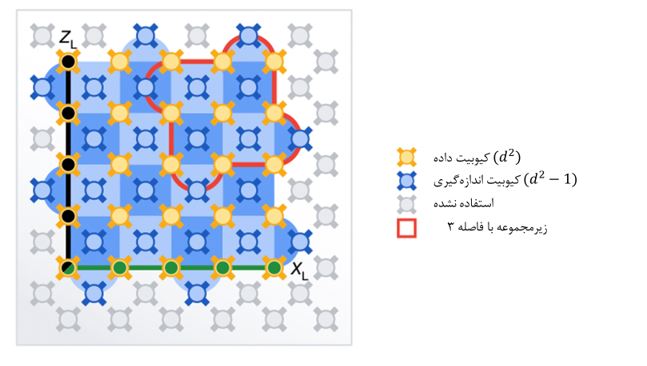
شکل 1:چیدمان تصحیح دو خطا. نمونه کوچک با خط قرمز مشخص شده و نمونه بزرگ با رنگ آبی سایه زده شده است.در هر دو مورد کیوبیتهای داده و تصحیح خطا در همسایگی یکدیگر قرار گرفتهاند.
یکسان، اما متفاوت
پاسخ گوگل به این مسائل، ساخت نسل جدیدی از پردازندههای Sycamore بود که تعداد و چیدمان کیوبیتهای سختافزاری قبلی خود را داشت. اما این شرکت تلاش کرد نرخ خطای کیوبیتهای جداگانه را کاهش دهد تا بتواند عملیات پیچیدهتری را بدون تجربه شکست انجام دهد. این سختافزاری است که گوگل برای آزمایش کیوبیتهای منطقی تصحیح خطا شده استفاده میکند.
مقالهای که در این زمینه چاپ شده است، بررسی دو روش مختلف را شرح میدهد. در هر دو، دادهها در یک شبکه مربعی از کیوبیتها ذخیره شده است. هر کدام از آنها کیوبیتهای مجاوری داشتند که برای اجرای تصحیح خطا روی آنها اندازهگیری انجام میشود. تنها تفاوت در اندازه شبکه بود. در یک روش، شبکه سه کیوبیت در سه کیوبیت بود. در دومی، پنج در پنج بود. اولی در مجموع به 17 کیوبیت سخت افزاری نیاز داشت. دومی به 49 کیوبیت یعنی تقریباً سه برابر نیاز داشت.
تیم تحقیقاتی طیف گستردهای از اندازهگیریهای عملکرد را انجام داد. اما سوال کلیدی ساده بود: کدام کیوبیت منطقی نرخ خطای کمتری داشت؟ اگر خطاها در کیوبیتهای سخت افزاری بیشتر بود، انتظار داریم سه برابر کردن تعداد کیوبیتهای سختافزاری، میزان خطا را افزایش دهد. اما اگر ترفندهای عملیاتی گوگل کیوبیتهای سختافزاری را به اندازه کافی بهبود بخشد، طرحبندی بزرگتر و مقاومتر نرخ خطا را کاهش میدهد.
طرح بزرگتر برنده شد، اما یک مشکل وجود داشت. به طور کلی، کیوبیت منطقی بزرگتر دارای نرخ خطای 2.914 درصد بود در حالی که کیوبیت کوچکتر 3.028 درصد نرخ خطا داشت. این مزیت چندانی نیست، اما اولین بار است که چنین مزیتی نشان داده شده است. و باید تاکید کرد که نرخ خطا در زمان استفاده از یکی از این کیوبیتهای منطقی در یک محاسبه پیچیده، بسیار بالاست. گوگل تخمین میزند برای اینکه بتوان مزیت کیوبیت منطقی بزرگتر را به وضوح مشاهده کرد لازم است عملکرد کیوبیتهای سختافزاری، حداقل 20 درصد بهبود یابد.
در یک بسته مطبوعاتی که همراه مقاله چاپ شده است، گوگل میگوید که در 2025-plus به آن نقطه میرسد – اجرای یک کیوبیت منطقی با عمر طولانی. در آن مرحله، با مشکلاتی مواجه خواهد شد که مشابه مشکلاتی است که IBM در حال حاضر روی آنها کار میکند: کیوبیتهای سختافزاری زیادی را میتوانید بر روی یک تراشه قرار دهید، اما شبکهسازی تعداد زیادی از تراشهها در یک واحد محاسباتی کار سادهای نیست. گوگل از تعیین تاریخی برای آزمایش راه حلهای این مشکل خودداری کرده است. (IBM گفته است که طی سال جاری و سال آینده رویکردهای مختلفی را آزمایش خواهد کرد.)
بنابراین، بهبود 0.11 درصدی در تصحیح خطا که تقریباً به نیمی از پردازنده گوگل نیاز دارد تا یک کیوبیت را میزبانی کند، هیچ نوع پیشرفت محاسباتی را نشان نمیدهد. ما از دیروز به شکستن رمزگذاری نزدیکتر نیستیم. اما این کار نشان میدهد که ما در حال حاضر در جایی هستیم که کیوبیتهای ما به اندازه کافی خوب هستند تا از بدتر کردن اوضاع جلوگیری کنیم – و مدتها قبل از اینکه ایدههای مردم درباره نحوه عملکرد بهتر کیوبیتهای سختافزاری تمام شود، به آنجا رسیدهایم. و این بدان معنی است که ما به جایی نزدیک شدهایم که موانع فنی که باید برطرف کنیم کمتر به سخت افزار کیوبیت مربوط میشود.